I like to read, I like to read the news, especially the New York Times. They have some of the best journalism in recent times, I like their data journalism, their opinion columns, and various stories that are not related to traditional ‘breaking news’. I also love their podcast “The Daily”. However, my favourite thing about The New York Times is their comment section on their articles.
It is truly a fantastic forum/community with great contributions from readers all over the word. Open to comments for 24 hours, it is moderated greatly by a human, thus leaving very little troll comments. A community I haven’t been able to see elsewhere on other publications.
What I love about the comment section is the organization of the comments.
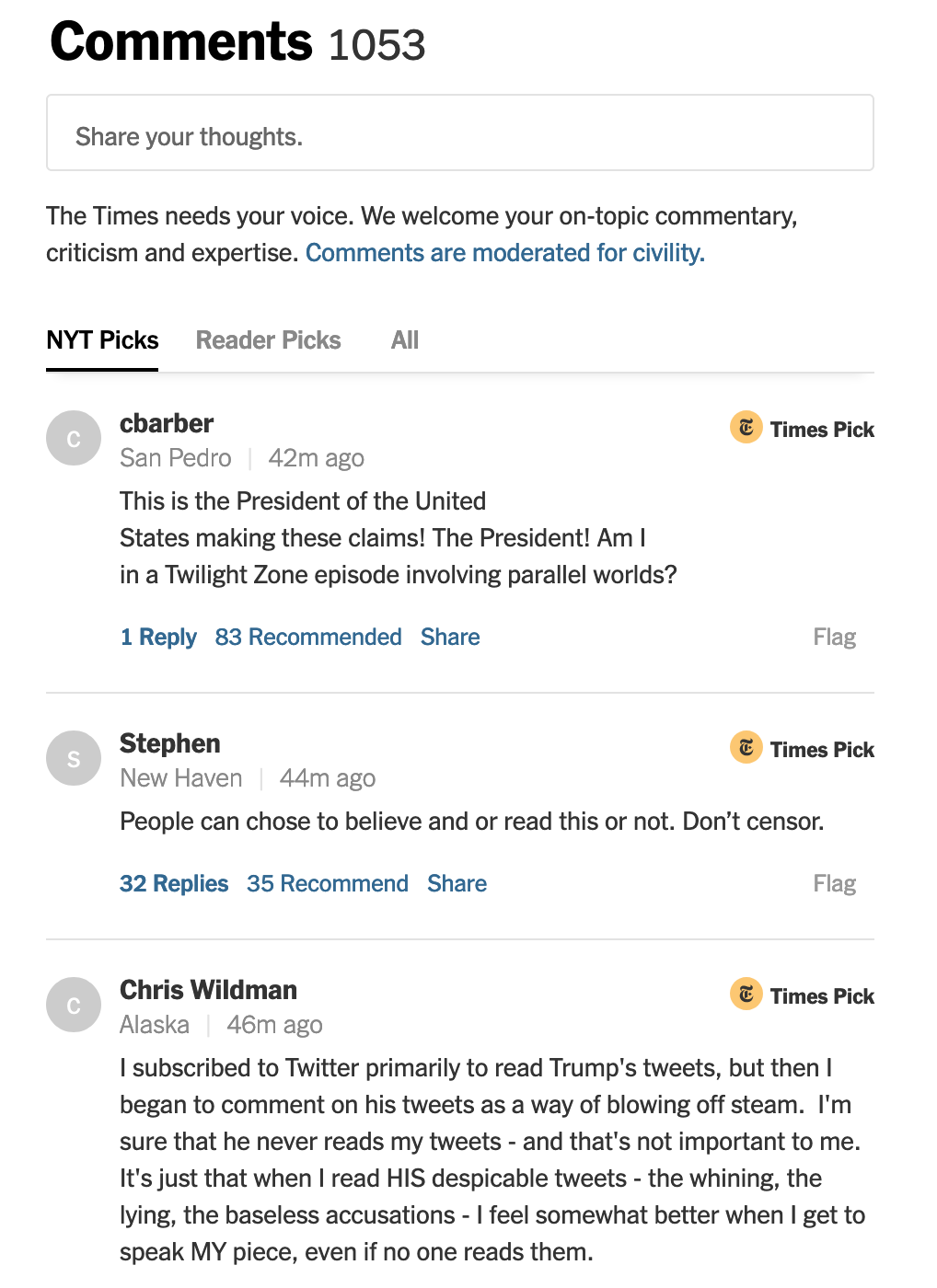
There are three tabs, the NYT Picks, Reader Picks, and All. Under the NYT Picks, the New York Times will highlight comments that represent a range of views and are judged as most interesting or useful, in regards to the topic of the article. The Reader Picks, are pretty much the highest upvoted and engaged comments. With All, allowing you to sort comments by newest or oldest.
I’ve recently found out that the New York Times have an API that can help us easily extract some of these wonderful comments and I’m going to show you how!
Step 1: Creating a NYT Developer account and your API key
- Go to https://developer.nytimes.com/
- Sign in or Create an account
- Go in Apps which can be access by hovering your mouse on your account name.
- Create a New App
- Provide a name and description
- Activate the Community API (which is currently in beta)
- Copy your API key to clipboard for further use
Step 2: Setting things up in Python
Note: We are limited to 4000 requests per day, and 10 requests per minute.
Note: We need to specify the offset since, each time we query our API, we can only get 25 comments at a time, getting comments from 25 to 49 will require us to set the offset to 25.
#The Basic Setup
#Required Plugins
import pandas as pd
import requests
#Your New York Times API Key
api_key = 'your_key'
#Article of the comments you want to scrape
nyt_article = 'https://www.nytimes.com/2020/05/24/opinion/biden-trump-coronavirus.html'
#offset
offset = 0
#Request URL for comments
request_url = f'https://api.nytimes.com/svc/community/v3/user-content/url.json?api-key={api_key}&offset={offset}&url={nyt_article}'
#request the data
r = requests.get(request_url)
#storing data into json format, however python will think it is a dictionary
json_data = r.json()
Once scraped, the json_data will look something like this.

Just from looking at the screenshot, you can easily tell there are some interesting features we could play with if we were to make a dataset out of this.
Such as:
- commentID
- userDisplayName
- userLocation
- commentBody
- recommendations
- replyCount
- replies
- editorsSelection
- recommendedFlag
- isAnonymous
Step 3: Extracting the data we want to a DataFrame
Note: The comments are located in the ‘results’ key of the dictionary.
#Stores in list with all the features
comment_list = json_data['results']['comments']
#each comment can be explored by index such as
comment_list[1]
#Store the list with the specific attributes to DataFrame
df = pd.DataFrame(comment_json, columns = ['commentID',
'userDisplayName',
'userLocation',
'commentBody',
'recommendations',
'replyCount',
'replies',
'editorsSelection',
'recommendedFlag',
'isAnonymous',])
Step 4: Easy Function to Scrape all the comments from the article, including replies.
#Extra Plugins
import time
def get_all_comments(api_key, nyt_article):
'''
Input:
api_key = Your API KEY (string)
nyt_article = link to the nyt article that has comments (string)
Output:
Pandas DataFame
This function will extract all the comments out of a NYT article, and stores it in a DataFrame
'''
#set offset to 0
offset = 0
#At some point the json_data['results']['comments'] will return an empty list
comment_body_check = ['test']
#empty dataframe to store data
comment_df = pd.DataFrame()
while comment_body_check != []:
#URL for scraping data
request_url = f'https://api.nytimes.com/svc/community/v3/user-content/url.json?api-key={api_key}&offset={offset}&url={nyt_article}'
#Get data
r = requests.get(request_url)
#Conver to JSON
json_data = r.json()
#Single out the comment section, it becomes a list
comment_json = json_data['results']['comments']
comment_body_check = comment_json
#create list
comment_list = []
df = pd.DataFrame(comment_json, columns = ['commentID',
'userDisplayName',
'userLocation',
'commentBody',
'recommendations',
'replyCount',
'replies',
'editorsSelection',
'recommendedFlag',
'isAnonymous',])
offset += 25
#append 25 scraped commentt
comment_df = comment_df.append(df)
#Sanity Check
print(f'Batch of 25 comments scraped at offset = {offset}.')
#6 second pause, so that the API doesn't get overwhelmed
time.sleep(6)
#resetting index for a clean output
comment_df.reset_index(inplace = True)
return comment_df
#To Run
comments_df = get_all_comments('Your API KEY','https://www.nytimes.com/2020/05/24/opinion/biden-trump-coronavirus.html')
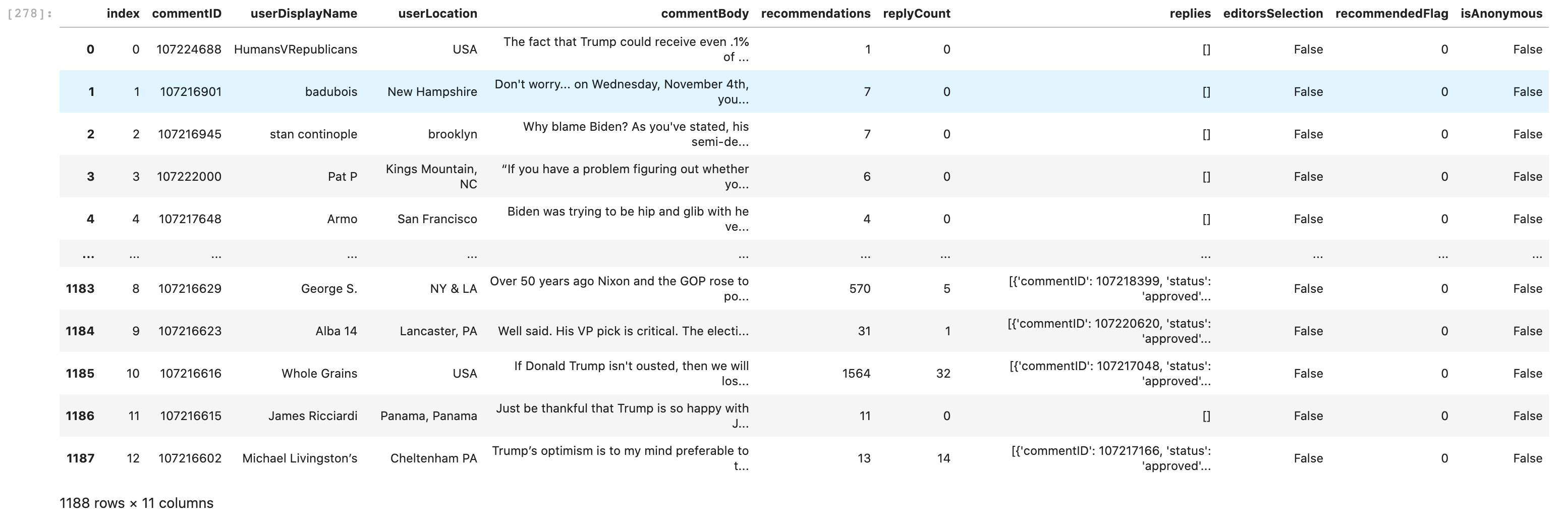
The Final DataFrame
Note: Our function and the API we used extracts all parent comments, all replies are not counted and are stored in the replies feature, to which will require further cleaning and manipulation.
However, the NYT Community API does have a separate request link for replies to comments for specific commentSequence. Here is how you set it up.
Note: Each request is still limited to 25 comment replies at a time, and we have to specify which comment we want to extract the replies from. To specify which comment we need to input the commentSequence which is the same as commentID, from what I’ve explored so far.
#Your New York Times API Key
api_key = 'your_key'
#Article of the comments you want to scrape
nyt_article = 'https://www.nytimes.com/2020/05/24/opinion/biden-trump-coronavirus.html'
#offset
offset = 0
#comment sequence = comment ID
commentSequence = 107216616
reply_url = f'https://api.nytimes.com/svc/community/v3/user-content/replies.json?api-key={api_key}&url={nyt_article}&commentSequence={commentSequence}&offset={offset}'
#request the data
r_reply = requests.get(reply_url)
#storing data into json
reply_data = r_reply.json()
However, you would be wasting your request quota for the day and you have already extracted those replies anyways from the previous function, and those replies are not subject to the parent comment limitations.
There ya go! Now you know how to extract all comments from a New York Times Article!